Hello Community,
With last week’s release of Website and Document ingestion features for AI Assist, here are some of the FAQs to help you get introduced:
Website Ingestion
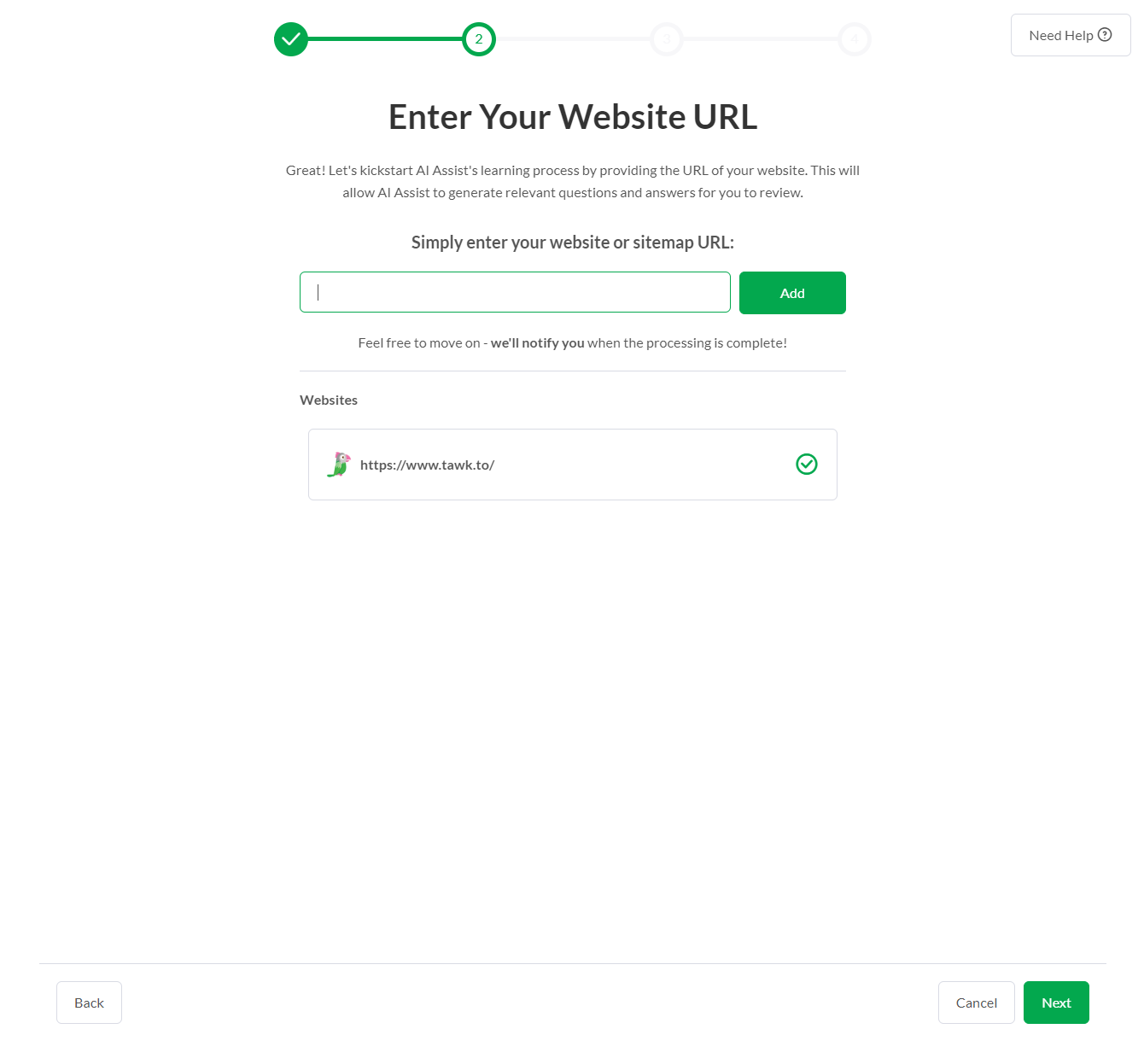
- What is the new website ingestion feature?
- Users can now input website and sitemap URLs. Web pages will be crawled, and the information will be added to the AI’s knowledge.
- How does the system handle URL redirects?
- If the provided URLs redirect, the system will internally store the final redirected URL.
- What criteria are used to determine which web pages will be ingested?
- For Websites: Only pages under the provided URL’s subdirectory. For Sitemaps: All pages under the sitemap URL’s domain.
- Is there a limit to the number of web pages that can be ingested?
- Ingested web pages for each unique URL are currently limited to 500. It is possible to upload multiple URLs with up to 500 unique pages each.
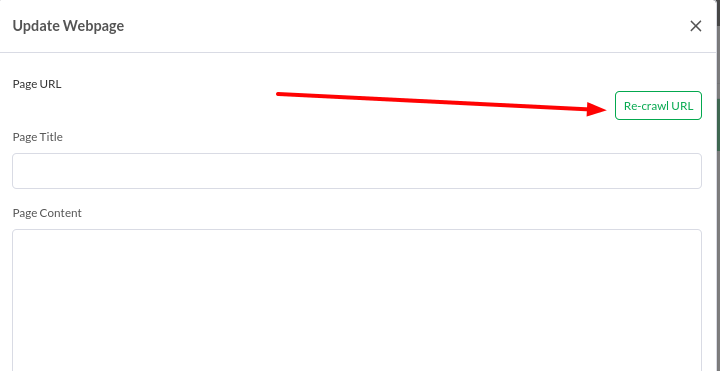
- Can users manually update or re-crawl web pages?
- Yes, users can manually update info such as title, content, searchable status, and initiate re-crawling of individual web pages.
- Are there any tags or class names that are omitted during ingestion?
- Yes, several tags like nav, script, footer, and class names like navigation, menu, ads, banner, etc., are omitted.
- Will website ingest automatically update if I change something on my site?
- Currently ingestion process is a one-off event, but we are looking into automating this in future updates.*
Document Ingestion
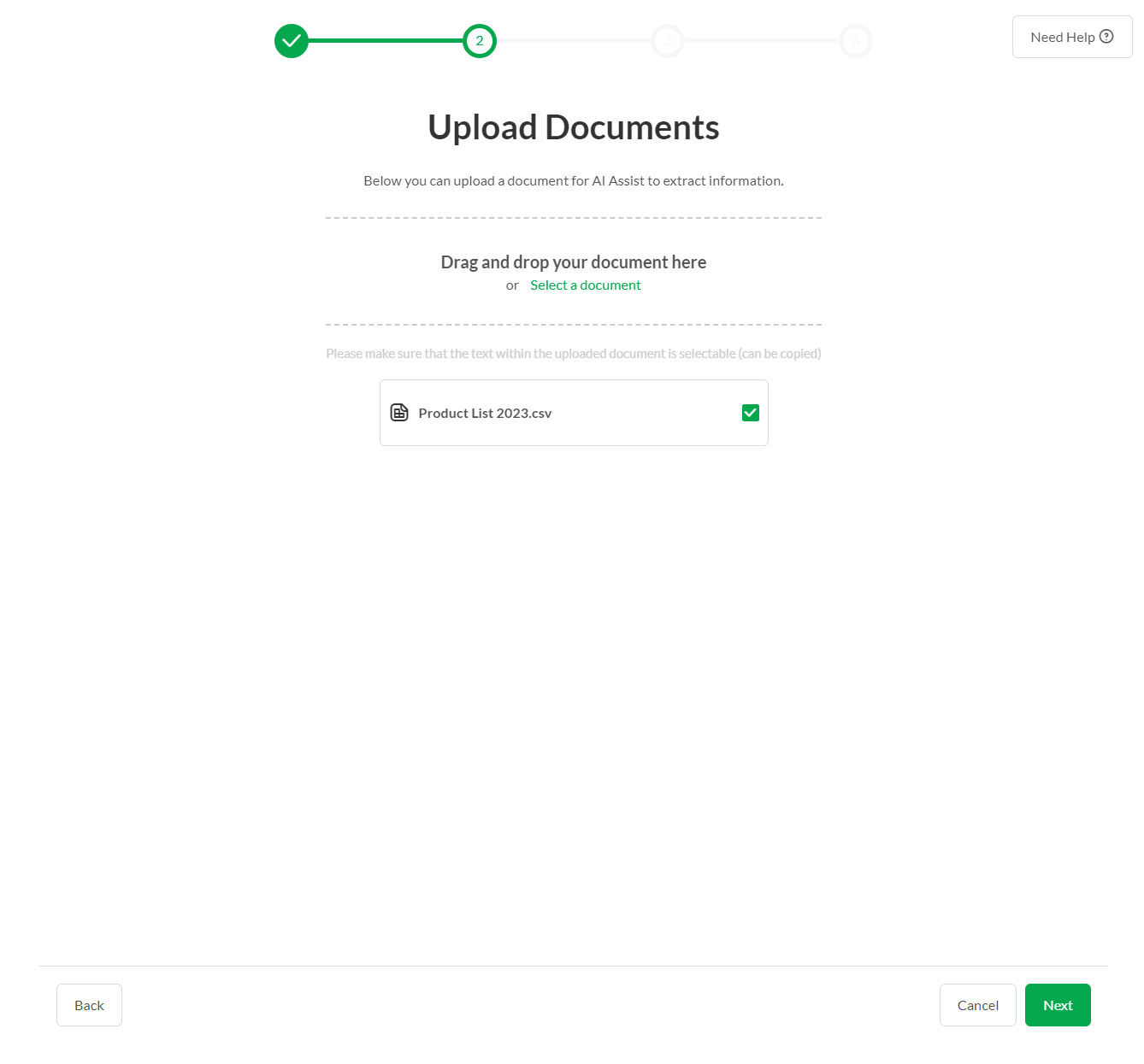
- What is the new document ingestion feature?
- Documents can now serve as a source of knowledge for the AI-assistant, supporting various types like PDF, TXT, and CSV.
- What are the limitations for PDF files?
- Only text is extracted, scanned images or empty pages are ignored, and the maximum size is 10MB. Text is split into 1000 character chunks.
- What are the limitations for TXT files?
- The maximum size is 5MB, rows greater than 1000 characters are ignored, and text is split into 1000 character chunks.
- What are the limitations for CSV files?
- The maximum size is 5MB, empty rows or rows with content-length greater than 1000 characters are ignored, and each row is considered a knowledge chunk.
If you have any questions of your own about these features feel free to reach out to us vai reply here on Community and we will help you find the answer.